Azure Data Factory’s data flows are designed to provide cloud-scale ETL and big data analytics with an east-to-use UI that can scale automatically without requiring data engineers to have to dig under the hood of Spark distributed computing.
One of the important features built into ADF is the ability to quickly preview your data while designing your data flows and to execute the finished product against a sampling of data prior to finalizing and operationalizing your pipelines.
However, there are a few fundamentals relative to working with Joins that you should keep in mind and a few details below are important to understand at design time and while debugging / testing.
Debugging generally uses limited data, so your join may fail or show NULL
This principle is actually valid for many any ADF Data Flow transformation types that are conditional on boolean formulas that look for specific data, i.e. Exists, Lookup, Filter.
What ADF does is to default to a 1,000 row limit from every source in your data flow. This enables a much quicker, snappier response from the interactive Spark session that is brought online when you enable the “Data Flow Debug” session. You can adjust this row limit with the “Debug Settings” option in the ADF Data Flow designer and is valid only during design time when using data preview for that session.
In this sample data flow, I have 2 sources: a flat file and a database source. Notice that ADF will prompt for row limits on each individually in the debug settings panel.
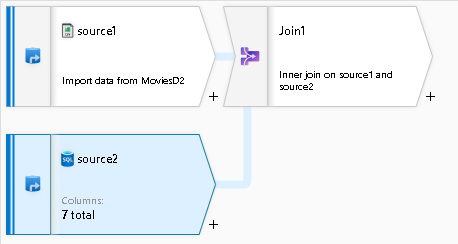

The effect that you will see with Joins relative to row limits is that ADF may not always find matches for your join logic when looking at partial datasets. This can result in side-effects in the data preview output that make it appears as if your join logic is incorrect or that there is an error in execution.

To artificially generate this error condition, I set my Join condition as an Inner Join first matching on the movie key column, then I set a condition that the Title from the incoming stream must start with the letter “S”:

My total dataset has about 9,100 rows, so with the default value of 1,000 for the row limit, ADF never made it to the movie titles starting with “S” from the two sources. Therefore, the Join failed, but only due to the limited number of rows for sampling. In other words, the limited rows did not include movie titles that started with “S”.
To fix this, I increased the row limit to 10,000 for each source and now all movies were available to ADF and the Join worked as expected. However, if you increase the data preview limit sizes exponentially, be aware of the impact to the underlying Spark compute resources. Make sure that you are running your debug session using an Azure IR that is memory optimized with enough cores for the number of rows that you are allowing for preview.
Another remedy for this scenario is to use specific data samples in your sources that contain known data that you can join on to test specific join scenarios. In the Debug Settings panel above, you’ll see the option to choose a sample file for the delimited text source and a sample table for the database source. You can load a text file and database table that have just the values that you wish to explicitly test in your flow.
Alternatively, in my demo, I could use the query property in the database source to only bring in movie titles that start with “S” to ensure that they would be part of the data to test with. This will ensure that the Join test will pass at design time:
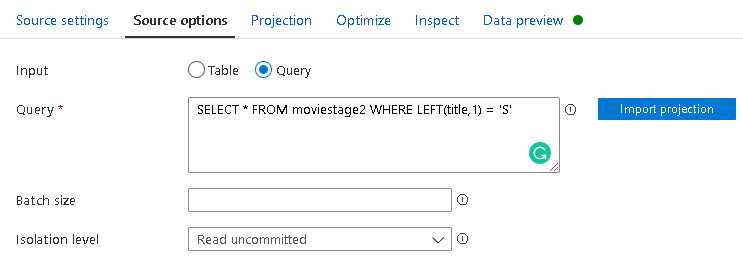
If you use this technique, just be sure to set the query back to the original intent of your source transformation. The advantage of the debug settings limit is that it is only honored in your current data flow design session so you don’t need to change your transformation logic.
Test data in debug pipeline
Next step in SDLC for ADF Data Flows is to test the data flow logic in a pipeline. While the debug session can use the warmed Databricks cluster, the debug settings to limit the number of rows is only honored in the data preview pane. To apply the same limits to your data flow at runtime, there is a setting in each Source transformation called Sampling:

Just remember to switch it back to “Disable” after you are done with your testing because this property will be read upon pipeline executions of your data flow activity. If you are testing against large datasets, be sure to choose the “Debug from Activity Runtime” option so that you can use a larger Azure IR that you have set for inside your data flow pipeline activity.


[…] Mark Kromer clears up some issues around debugging in Azure Data Factory: […]
Great article! Hoping you may have seen this join error before, where the (small set of) rows doesn’t match same ID between streams that originated in Excel and SQL datasets? Match works when I join two SQL DB datasets though 😦
https://docs.microsoft.com/en-us/answers/questions/462490/join-not-matching-same-ids-creating-null-rows-inst.html
Thanks for the blog! So does that mean when you publish and trigger a run (not debug), the ‘Sampling’ needs to be disabled so that all records get picked up for processing?
Yes, when executing the data flow from a triggered pipeline, if you still have sampling enabled in the source, ADF will use that sampling limit instead of reading the entire dataset.
That clarifies so many things! Thanks!
Could you please tell me, so, the recommendation is to Disable the ‘Sampling’ option before a full triggered run? I assumed the sampling records are only used while debugging and when ‘triggered’ ADF will default pick all records.
Can you please clarify?