The pipeline template for this solution can be found here.
Processing delimited text files in the data lake is one of the most popular uses of Azure Data Factory (ADF). To define the field delimiter, you set the column delimiter property in an ADF dataset.
The reality of data processing is that delimiter can change often. ADF provides a facility to account for this data drift via parameterization. However, this assumes that you know that the delimiter is changing and what it will change to.
I’m going to briefly describe a sample of how to auto-detect a file delimiter using ADF Data Flows.
The pipeline will look something like this:
- Data flow that detects the field delimiter from the first row in the text file and outputs the delimiter to a blob text file
- A Lookup activity that reads that delimiter from the text file and sends the delimiter character to your processing step
- In my example, my actual processing work is done in the final data flow activity using the dynamic delimiter parameter
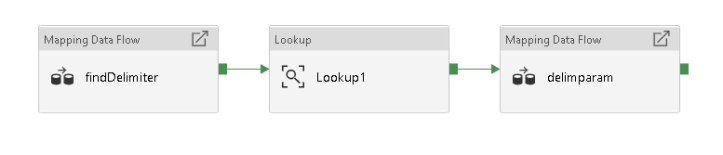
Find Delimiter Data Flow
This is where the text file delimiter is detected. Start with a Source in a new data flow that uses a dataset that will read your file as rows of strings.

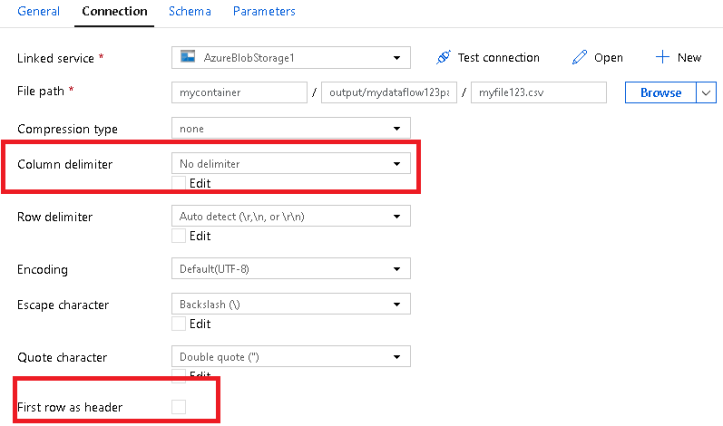
The source dataset should have no field delimiter and no header set. This is because we just want to read each row as a whole string and then just take the first row. You’ll want no schema in the dataset and no projection in the Source transformation.
The next transformation is a Derived Column which will create a metadata field to hold the row value. The default for a field without a header in ADF data flows is ‘_col0_’. That’ll be fine for this demo, but you can always change that to something more meaningful.
Now that we have stored the rows as strings, we just want to work with the first row. So I used a Surrogate Key transformation to number each row uniquely with an incrementing value that I called ‘rownum’. I then used a Filter transformation that filters out the other rows with this simple formula:
rownum == 1
When we make it to the Derived Column transformation, we’re only working with the first row from the file. This is where we will use regex to find the delimiter for this file. You can add any other special characters that you want in this expression. Or you may even have a better regular expression than mine. I will be the first to tell you that I am not expert-level at regex!
'Delimiter:,'+toString(regexExtract({_col0_},'([!$`~%^,|\t])',1))
I called the new column ‘delimiter’ and I’m using regexExtract. This will output regex groups for each match. The 3rd parameter in the function above tells ADF to take the first matching group. The 1st param is the incoming column name that we set above. And the 2nd param is where you use your regular expression which is inside single quotes using the grouping parentheses and the square bracket for lists.
Because this is looking at your entire row of data, not delimited, the first of those special characters that is found will be returned as the file’s delimiter. The reason for prefacing the string with ‘Delimiter:,’ is because we will read this output from a delimited file in the Lookup activity. More on that soon …
Lastly, sink to a new text delimited file using comma as the separator and do not include headers.
In the Sink, map only the delimiter field. We just want a very small, simple file that tells us what the dynamic delimiter will be.
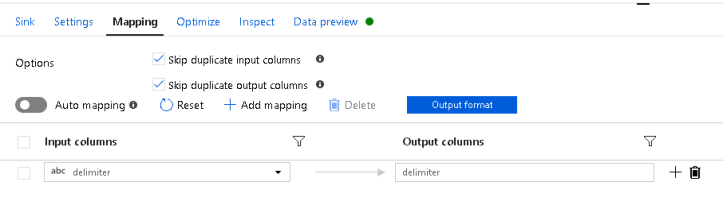
I’m using ‘output to single file’ and naming my output file as this:

Lookup Activity
The Lookup Activity will now read that ‘delimiter.txt’ file from the above step and parse out the dynamic delimiter, sending it to your final action activity as a parameter.
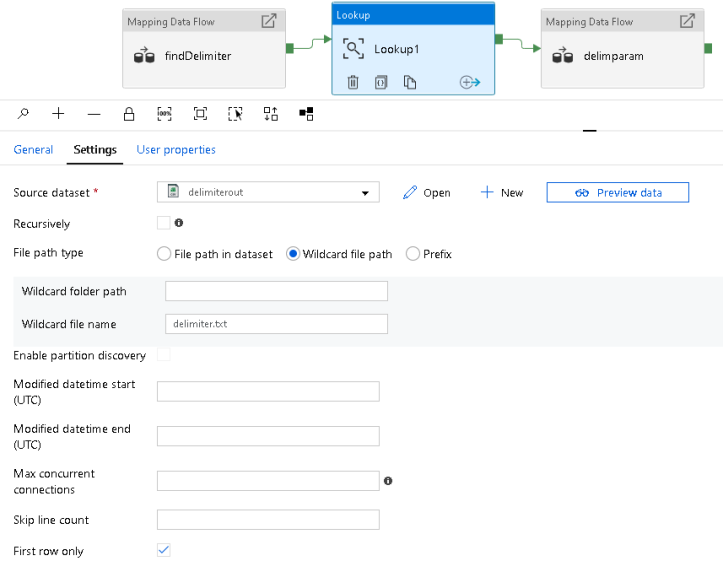
Final Activity
In my example, I’m using a data flow for processing. In your pipeline, you can use any activity next. The idea is to now pass that delimiter to the column delimiter property of the dataset being used at the end of your pipeline. You do this by grabbing the output of the firstRow property from the Lookup in your last activity:
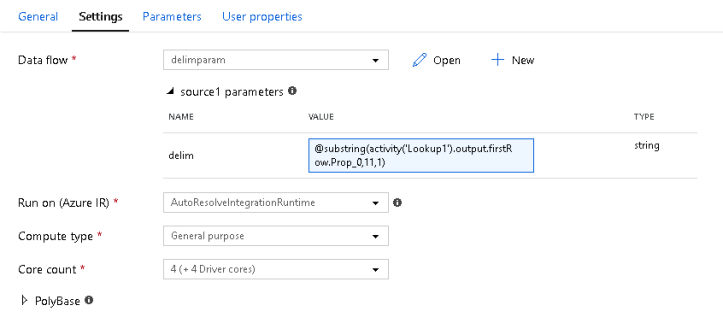
The formula for the ‘delim’ property in the dataset is:
@substring(activity('Lookup1').output.firstRow.Prop_0,11,1)
What that does is to parse out the prefaced text ‘Delimiter:,’ and just take the single character delimiter that was discovered from the source file. The definition for the dataset that we’ll use in the final processing step will look something like this below where we set the column delimiter to a parameter called ‘delim’ set in the dataset parameters: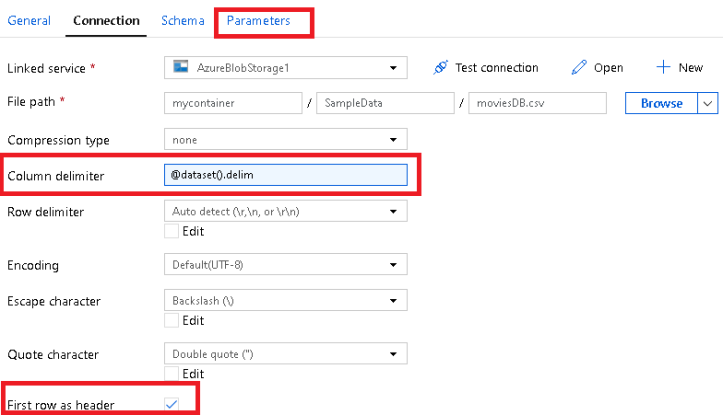
When you execute this pipeline, the first step will discover the delimiter, Lookup will read it from the temp file and pass it to your final step as a dataset parameter.

[…] Mark Kromer shows us a way of dynamically learning what the likely delimiter of a delimited file is: […]