Here are a few quick tips to help with improving the performance of Join in ADF with data flows:
Managing the performance of joins in your data flow is a very common operation that you will perform throughout the lifecycle of your data transformations.
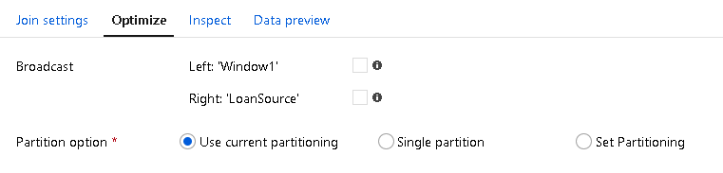
Broadcast optimization
In ADF, unlike SSIS, data flows do not require data to be sorted prior to joins as these operations are performed as hash joins in Spark. However, you can benefit from improved performance with the “Broadcast” Join optimization. This will avoid shuffles by pushing down the contents of either side of your join relationship into the Spark node. This works well for smaller tables that are used for reference lookups. Larger tables that may not fit into the node’s memory are not good candidates for broadcast optimization.
Avoid literals in join conditions
When you include literal values in your join conditions, Spark may see that as a requirement to perform a full cartesian product first, then filter out the joined values. But if you ensure that you (1) have column values from both sides of your join condition, you can avoid this Spark-induced cartesian product and improve the performance of your joins and data flows. (2) Avoid use of literal conditions to represent the results of one side of your join condition.
In other words, avoid this for your join condition:
source1@movieId == '1'source1@movieId == dummyvaluea.empid == b.empid && a.code = 10
Duplicate columns
Test, Test, Test
As with everything in data engineering, please test your Join conditions in ADF Debug pipelines before deploying. Look at the results of your data flow debug execution in the monitoring view to see if the Join is performing to your expectations.
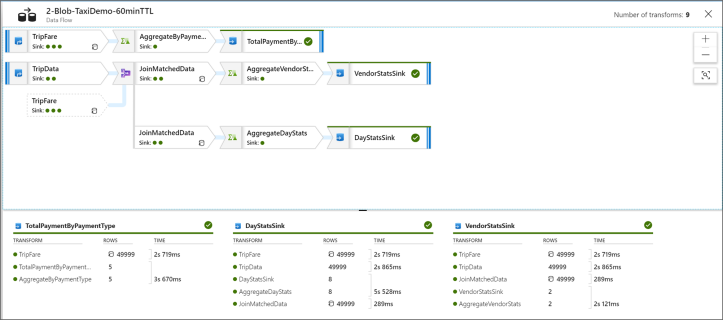
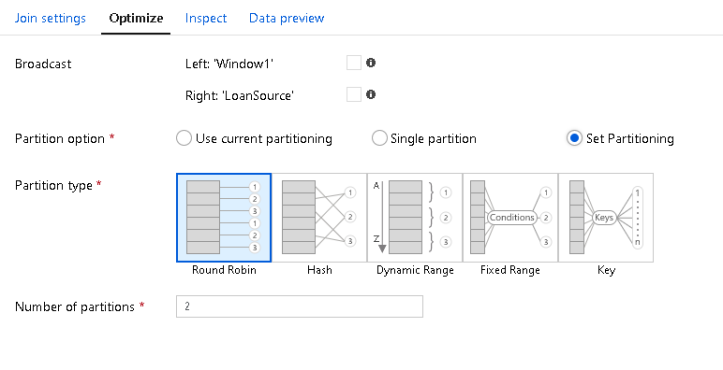
In this sample execution plan, you can see that the Join is taking less than 1 second (see the timings at the bottom in the middle lane). You will not be able to optimize this further. However, if you see joins taking several minutes, you can add broadcast optimization and look at partitioning data in your join. Click on the Optimize tab of your Join transformation and you will see that ADF allows you to control the data partitioning in your join. If you do not have detailed information about your data value distributions, you can use round-robin partitioning. If you have a good understanding of your data cardinality and values, you can set the rules for hashing:

[…] Mark Kromer has a few tips on improving ADF data flow join performance: […]
Are there any size limitations such as max number of records supported in join operation