A very common pattern in ETL and data engineering is cleaning data by marking rows as possible duplicate or removing duplicate rows. Azure Data Factory Mapping Data Flows has a number of capabilities that allow you to clean data by finding possible duplicates.
- Here is a video example of this technique in ADF and Synapse Analytics using data flows
- You can also use regex inside of ADF Data Flow for pattern matching instead of exact string matching
- Here, we’re going to talk about using Soundex in ADF’s Mapping Data Flow expression language, which uses the Spark Soundex function. The full expression language available inside ADF’s Mapping Data Flow transformation can be seen here.
With Soundex, we can perform fuzzy matching on columns like name strings. Soundex provides a phonetic match and returns a code that is based on the way that a word sounds instead of its spelling.
Let’s walk through a sample … the JSON code for this sample data flow is here.
-
-
-
- In this demo, the source will be a CSV file. I found some good random name samples with a number of other interesting attributes like phone number, address, gender, etc. here. I took the smaller 100-person sample set and modified a bit to throw in some duplicates for testing. You can download the 90-name dataset here in CSV format that I used for this sample. I added the likely matches at the very end of the file using IDs 111111,222222,333333.
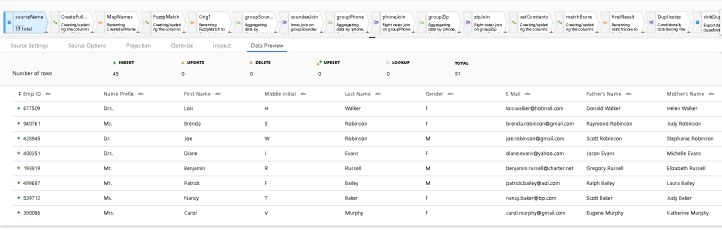
- I added a few transformations directly after the Source so that you can utilize other datasets in the Source transformation so long as you can normalize a full name, zip code, and phone number fields. You can also take this sample pattern and use other source attributes that you wish to use to determine if there are duplicate rows. Just map your own source’s columns names to the target names in the MapNames Select transformation.
- In this demo, I am looking at only phonetic sound of full name, zip code and phone number as matches.
- The Derived Column sets the full name from the demo CSV:
{First Name} + ' '+{Last Name} - The 3rd transform is a Select transform which I am using to map incoming full name, zip, acct number, and phone number to the canonical model of this deduping model sample. This is where you can match your own data to my canonical model.
- The 4th transform is where we use Soundex. The ADF Data Flow expression formula is simply:
soundex(fullname) - This will produce a Soundex code for each row based on the full name column value

- The Soundex Value is a phonetic value that is produced by the full name string
- With ADF Mapping Data Flows, you’ll note that we build our flows in a left-to-right construction paradigm
- In this model, I’ve used a self-join pattern in a number of occasions. The self-join pattern is documented here.
- Each of the thick vertical lines you see in the designer is called a New Branch, which duplicates the current data stream. This technique allows you to perform operations on your data, like aggregations, then join in back later to gather all original data columns.
- You will find subsequent Join transformations following the branch which joins the data back into a single stream.
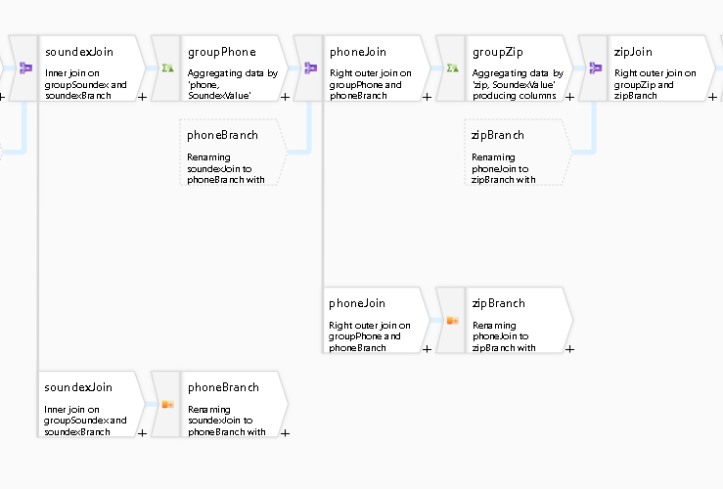
- There are 3 Aggregate transformations in the data flow that allow me to use grouping so that I can group Soundex, Phone, and Zip by common values, thereby identifying duplicates. This is how to find distinct values in ADF Mapping Data Flows.
- Once you use an aggregate, the data reduces to only the columns that are used in your aggregate functions & groupings. This is why I’m using the self-join approach above. So now I can rejoin all of the original columns and perform multiple aggregations to find duplicate values in full name (via Soundex phonetics), phone, and zip.
- The way to use an aggregate to find duplicates is to use the SUM(1) function in your aggregate expression. If the resulting count is >1, then you know that you have more than 1 entry in your data matching that value.
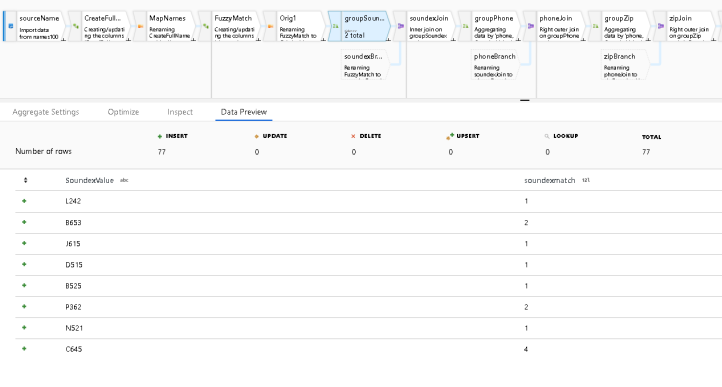
- This is an example of the results in the Aggregate transform called “groupSoundex” which is grouping all names that sound alike. Any time the value is >1, we know we have possible duplicates:
- Once we perform this same aggregation technique on every attribute that we are interested in, we can assign weights to each so that we can generate a match probability score.
- In this demo, I’m only interested in similar sounding full names, exact phone, and exact zip matches. You may wish to use more attributes for your models.
- The Derived Column transformation called “setConstants” is where I am building my scoring model. You can adjust the weightings and model attribution in this Derived Column transformation accordingly to your model:
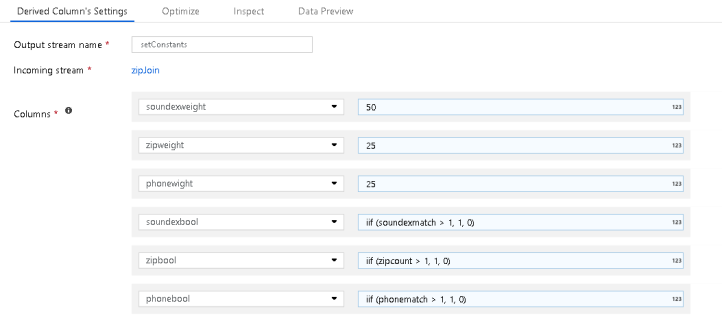
- I’m giving the sounds-like full name value a weighting of 50, 25 to zip matches, and 25 to phone matches.
- I’m also creating yes/no booleans for the aggregate sums. This way, I can calculate a value up to 100 by using a 0/1 for more than 1 match.
- That calculation is available in the next Derived Column called “matchScore”:
(soundexbool * 50) + (zipbool * 25) + (phonebool * 25) 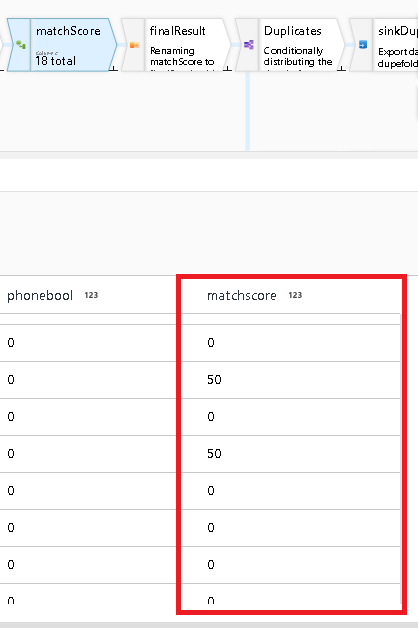
- Now that I have my formula, we’re at the end of the process. I use a Select transformation to select the fields that I am interested in storing: acctnum, phone, zip, full name, matchscore
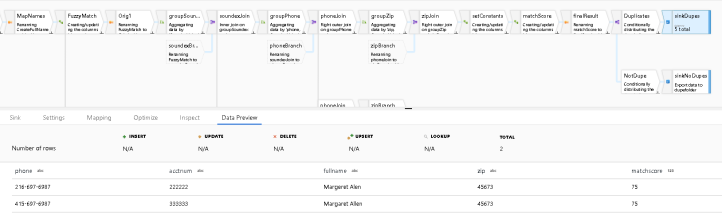
- I use a Conditional Split so that I can write two files: one file contains the unique rows, the other contains the rows that have >50% chance of being a duplicate using this formula in my conditional split transformation:
matchscore > 50 - When you look at the top row Sink, which is writing out the likely duplicate rows, you see that there is a 75% that these are duplicates:
- When you look at the bottom Sink which is writing out the unique rows, you see that ADF chose this version of that same name as unique:
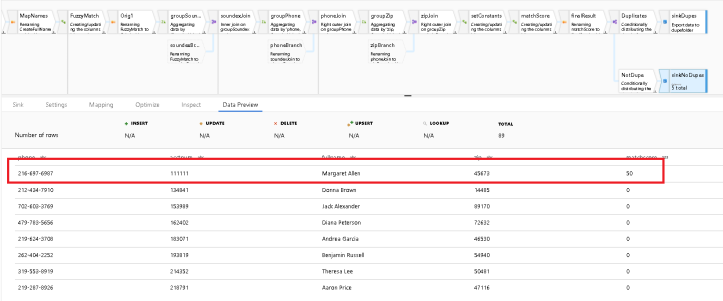
-
-

[…] Use ADF Mapping Data Flows for Fuzzy Matching and Dedupe Fuzzy Matching with Spark Soundex function in ADF sounds interesting! […]
This is a great solution, I’m trying to do something similar with Levenshtein distance. I have a list of books and authors of which I’m trying to identify the duplicates/editions. I can’t really use soundex since the book titles are typed in. I have over 2.5M books. Is the only way to compare each string (6.25 trillion). It might be possible to first compare author name but I need a way to ignore order. Azure Search gives pretty good results but I don’t think there is a way to quickly query the index. Please let me know what you think the best approach is? Thanks!