Azure Data Factory’s new Data Flow feature (preview) enables you to build visually-designed data transformations that execute at scale on Azure Databricks without coding.
One of the most powerful features of this new capability is the ADF Data Flow expression language that is available from the Expression Builder inside the visual transformations:
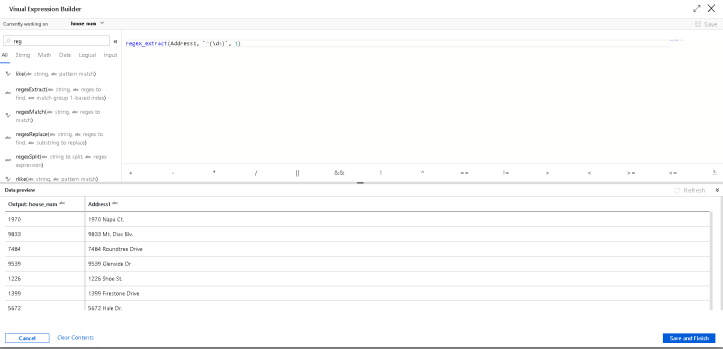
In this post, I want to focus on the Regular Expression functions that are exposed in the expression language.
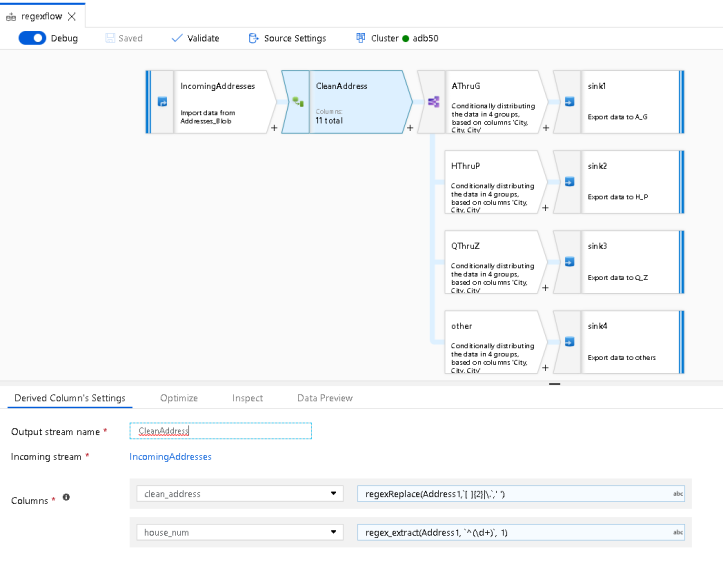
I’m going to work with address data from CSV files in Azure Blob Storage that I’ve added as my Source Transform called “IncomingAddresses”. From there, I’m using a Derived Column Transform to create a “cleaned” street address and a separate house number field.
After that’s done, I’m splitting the data stream by the first letter of the City field into A-G, H-P, Q-Z and any other (i.e. junk) data that can each sink their data streams into new folders in Blob Storage.
In a real-world scenario, you would likely have more work and cleaning to do to your address data before sinking it, possibly to a database destination. But rather than add more transformation steps, I wanted to keep this example simple in order to focus on using solely regular expression functions for these actions.
The first Clean Address derived column action uses regexReplace.
The full list of ADF Data Flow expression language functions is available here at this link.
regexReplace(Address1,`[ ]{2}|\.`,' ')
This will take the Address1 field, which contains street address strings, and replace any occurrence of 2 spaces or dots “.” with a single space. Regex can be tricky, complex, error-prone, and difficult to decipher. The best way to use Regex in ADF Data Flow is to enter Debug mode by switching it on from the Data Flow design surface.
This will open up an interactive session with your Azure Databricks cluster so that you can interactively test and debug your Data Flow. Directly inside the Expression Builder, you’ll be able to see the results of your transformation expression code, so that you can debug your regular expressions in real time:
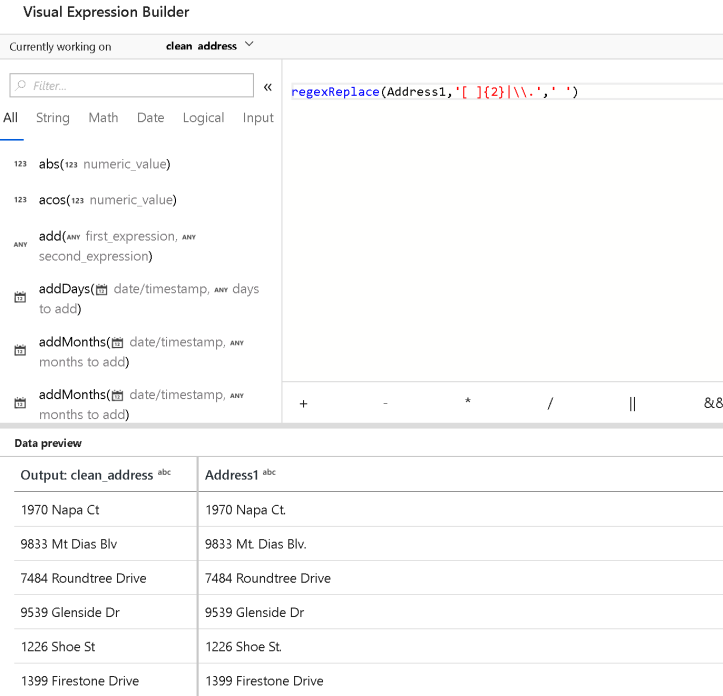
This way, you can play with your regular expressions with your actual data. Note that when you work in the Expression Builder in ADF Data Flows, you have support for auto-complete of all entities in the metadata and expression language with guides and help for function names and signatures:
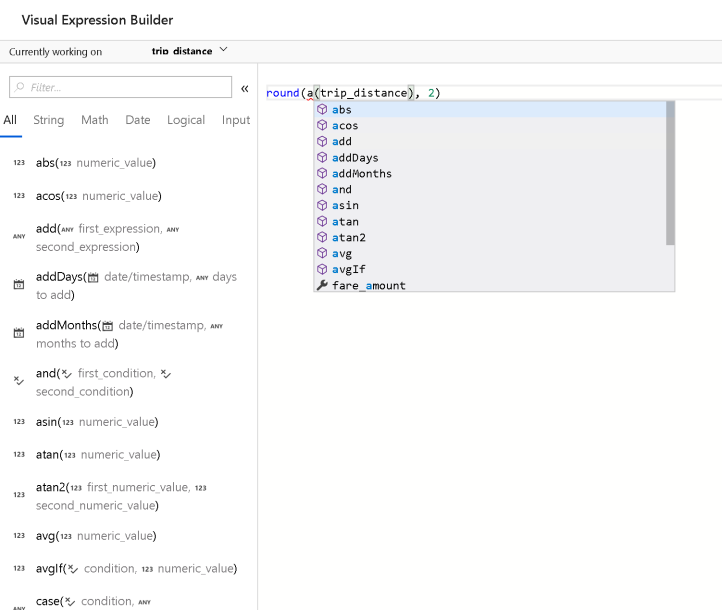
The 2nd Derived Column expression takes the street address and takes just the house number to generate a new column called “house_num”:
regex_extract(Address1, `^(\d+)`, 1)
The regex_extract function will use a regex pattern to extract terms from a string. The resulting value is a 1-based index, so you can refer to the matching terms as 1, 2, 3, etc. In this case, I just want the first term, which is the street house number.
The last example in this demo is using the Conditional Split Transform. I am using this to route execution of my data flow through streams that are split by the first character of each row’s City column value: A-G, H-P, Q-Z and then “other” is there to catch any bad data for City:
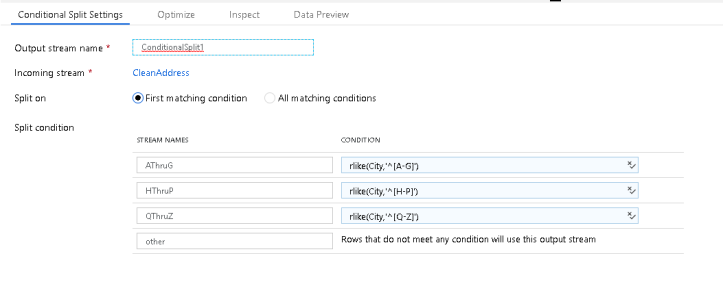
To do this, I’m using rlike, which allows me to enter a regular expression to match strings inside a column. In this case, I’m looking at each City value’s starting character which allows me to route the stream based on that character value:
rlike(City,'^[A-G]')
If you would like to play with this ADF Data Flow JSON from this sample, you can grab it from my Github repo here. Add the JSON to your Git repo in ADF and it will show up in the UI under Data Flows.
- The data that I am using is available here.
- To gain access to the ADF Data Flow preview, please request access here.
- Click here for the full set of ADF Data Flow documentation.

[…] Azure Data Factory Data Flow: Transform Data with Regular Expressions In this post, Mark Kromer (T) shows how regular expression can be used in ADF to clean an address. […]
[…] can also use regex inside of ADF Data Flow for pattern matching instead of exact string […]